
前回の記事で、モールス信号読み取りプログラムの大枠を作って紹介しましたが、モールス信号のオンオフパタンの読み取りは原始的な方法でお茶を濁してしまいました。今回はそこを強化してみた、という記事です。
モールス符号の入力を実際に理解させるときに、大きく二つ問題があります。
- 全く同一のタイミングで別の符号パタンが存在する
- モールス信号は人手で叩くこともあり、タイミングは必ずしも正確ではない
全く同一のタイミングについては、例えばこのようなもの
****** ****** ******これは、トンの長さが文字二個分と認識すると”T T T” になって正しいコードです。トンの長さを文字六個分と認識するとこれは “S” になってこれも正しいコードです(SOS の S です)。
モールス符号のタイミングのブレで読み取りが紛らわしい問題については、実際にテストパタンで経験したものでは例えば
***** *************** *********** ******これは P (.–.) のつもりですけれども三番目の信号が何かあいまいで L (.-..) とも読めてしまいます。他にも隙間があいまいで単なる信号の切れ目なのか文字の切れ目なのか判別がつけづらいという場合もありました。
前回は、こういった問題に対処するために、最初は「常識的な速度」をもとに判断し破綻し、その次に「最初の隙間は信号の切れ目、トン一つ分」と仮定してお茶を濁したわけですが、そんな仮定は成り立たない場合はいくらでもあるわけです。試しに前回のプログラムにコード “T T FINISHED” を入力してみましょう。パタンファイルは github レポジトリで見ることができます。
$ ./read_morse ../data/t-t-finished.wav
....................-.. ?最初に入ってくるパタンは ****** ****** ** ** ****** ** ... という感じで、最初のスペースをトン一つ分と考えるのでひたすら「トン」だけが入ってきたと判断、結果一文字もコードを読み取れずに終わってしまいました。
これは改良が必要です。単純に紛らわしいパタンが入ってきたら両方を試してみることにしましょう。試してみてそれが誤認識なら破綻するだろうから、そうしたらその可能性を切って行くという考えです。ということで実装してみました。名前はけれん味たっぷりに「多重世界線方式」にしましょう。もう還暦近いですが心は中二。
「POC は一日で組める、動くソフトは一週間、ちゃんと動かすには三か月」「発想は単純でも実装は地獄」というソフトウェアあるあるに遭遇してしまいプログラミング作業がえらいことになっていますがとりあえず動きました。どんな結果が出るか楽しみです。さっそく先ほどの “T T FINISHED” を食わせてみましょう
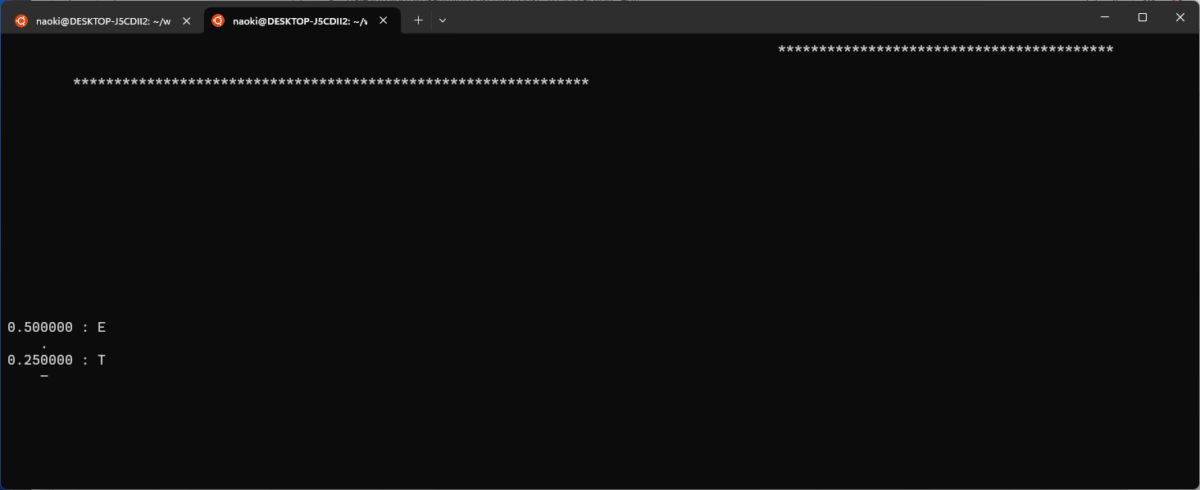
読み取りをスタートしてすぐ、最初の T が読み取られたところです。目論見通りプログラムは E かもしれない T かもしれないと両方を候補に出しています。各行の最初に出てくる数字は「自信度」ですがこれは読み取りが進むにつれて減少して行き絶対値にはあまり大きな意味はありません。相対値が重要で、プログラムの表示ではこの値が高いものを上位に持ってきてます。今のところ T は第二候補です。読み取りが進むとどうなるでしょうか?
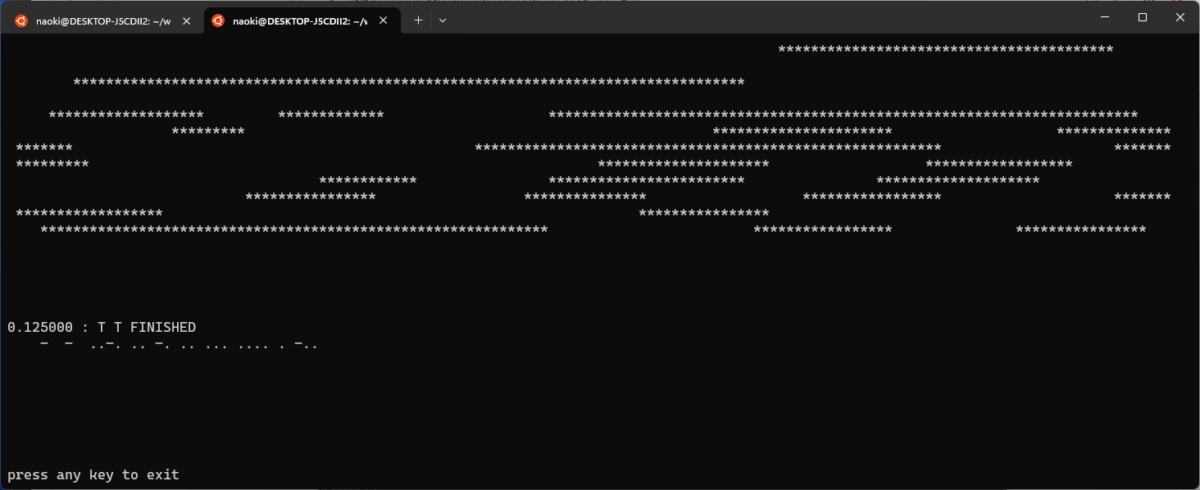
最終的には E で始まる読み取りは破綻して消えてしまいまい、”T T FINISHED” という読み取りだけが残りました。正解です。この方法で行けそうな感じです。
別のパタンも試してみましょう。今度はトンで始まる何かを読ませたいので “SPECIAL” にしました
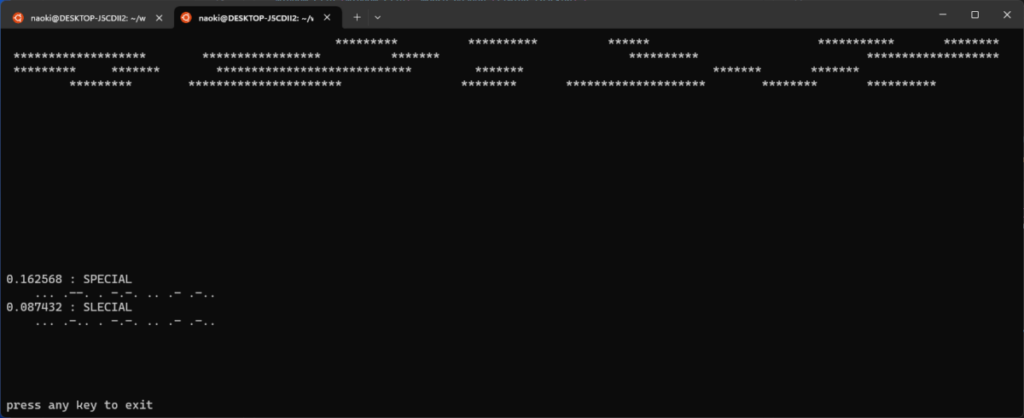
なんと、今度は最後まで生き残ってしまった誤認識があります。でも、自信度で判断すると下に来ました。
この自信度はどうやって決めているかというと、世界線の分岐があるたびに減ってゆきます。最初の自信度は 1.0 で、世界線が分岐するときに今持っている自信度を二つの世界線に分けます。その割合は、どちらも正しくて判断がつかない場合 0.5 : 0.5 に、タイミングのぶれのために不確かな場合はよりありそうな方に重みを付けます。どちらか正しいか判断がつかない場合にも 0.5 : 0.5 で割り振られます。今のところ「自信度」は一旦減ると二度と回復することはありません。これには狙いがあって、誤認識した場合タイミングのつじつまが合いにくくその後も分岐が起きやすくなる(はず)なので、誤認識した場合急速に自信度を落としてゆくことになる(んじゃないかな)、という目論見です。実行を繰り返して観察したところこの予想はある程度あっているようですがどれぐらいの信頼性があるかはもっと実験が必要そうです。
さらにもっと長い文章を入れたらどうなるでしょうか?僕が文字列テストでよく使うお気に入りのあれをやってみましょう
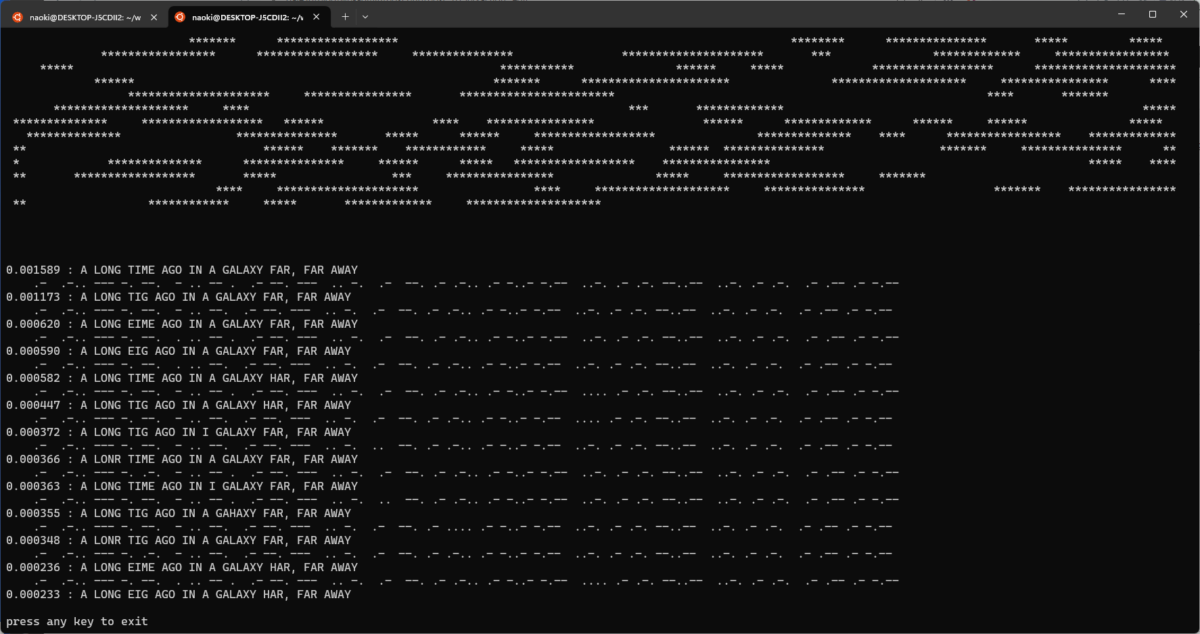
えらい数の分岐が生き残ってしまいましたが、一応正解がトップに来ているようです。こんなに候補を出していては実用的でないので効率的に刈り取りを行うのが次の課題です。
このプロジェクトの最新のコードは github で見られます
https://github.com/naokiiwakami/morse-code-reader
これは、プログラムがモールス信号の読み取りをしているところをスローモーションで撮ったところ、特に前半に分岐が起こったり順序が入れ替わったりするさまを見るのは楽しいです

