
ここ数日モールス符号のデコードアルゴリズムを書いていました。何故かというと、ラズパイでモールス信号の読み取り機ができるんだろうか?と突如疑問に思ったわけなんです。スマホが音声認識してしまう時代にモールス信号なんて、できても虚しいのでは?という自問に負けず、それでもやっぱりちゃんと機構を組んでメカメカしく動くものを作ると見えてくる物事の本質もあるはず。いやそんなメカちょっとみてみたい、と、復号化だけでなく信号を読むとこ全部やってみることにしたわけです。
一から全部ラズパイで作業すると独特の難しさが出てきてしまうので、具体的には暑い日に重たい仕事をラズパイにやらせるといい確率で何かが壊れたりするので、やれる確信を得るまでは PC を使って感触をつかんでいきます。そう考えると PC って頑丈にできていますね。連日の猛暑にファンもぶんぶん回って稼働していますが壊れずにいるのはすごいことなのかもしれません。
さてまず例題になりそうなモールス信号の入ったオーディオファイルを探してきてデータを見てみます。波形を見たところ、単純に音量でスイッチしても動作しそうです。でもそれではいくらなんでもノイズに弱すぎるかもしれません。
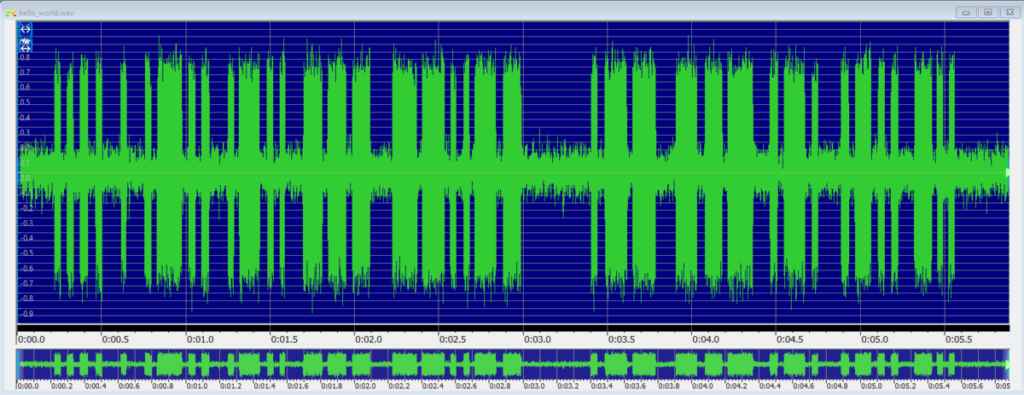
モールス信号はきれいな正弦波ですから FFT をかけて周波数領域で処理したらきれいに分離できるかも、と、やってみました。
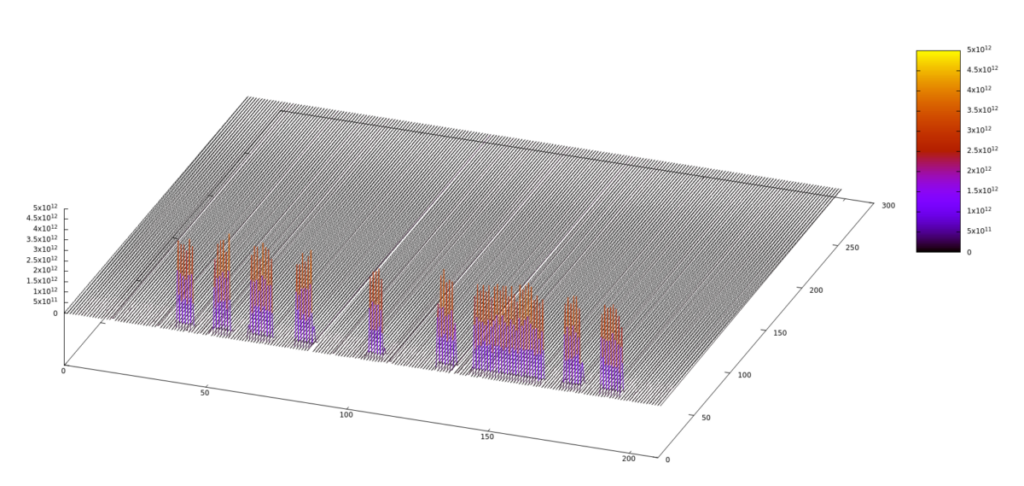
単一周波数上にはっきりとしたモールス符号のパタンが見えます。モールス信号はやっぱり周波数領域で感知したほうが良さそうです。でもここは後でしっかり時間をかけて検知方法を探るとして、今は適当に閾値を設けて周波数軸上をスキャンし、なにか拾ったらオン、という「とりあえず」な方法で済むか見てみました。
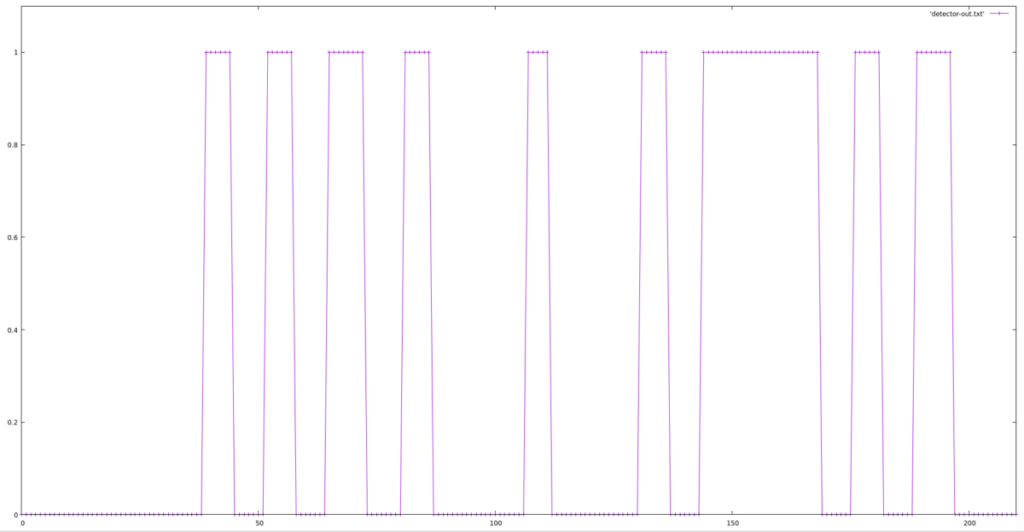
例題ファイルではそれで済むみたいです。ここはとりあえず動くようにしておいてさっさと先に進みましょう。
信号のオンオフを検知したその次は、オンになった時それが「トン」なのか「ツー」なのか判断しなくてはなりません。トンツーの見分けは人間には「見りゃわかるだろ」「聴きゃわかるだろ」と楽勝ですが、コンピュータはあいまいさを扱うのが大の苦手です。短いのがトンで長いのがツーだよ、といったって、短いとは具体的にどれぐらいですか何ミリ秒ですか?と、友達をなくしそうなことを聞いてくるのがコンピュータです。モールス信号は具体的にツーはトンの三個分など、長さはきちんと定義されていて、最初の信号がトンなのかツーなのかわかればあとは機械的に決められます。人間が手で打つせいでぶれがあるかもしれませんが判断基準に幅を持たせれば問題なさそうです。問題は、一個めが「トン」なのか「ツー」なのかどうやって決めるかということ。まずは「常識的なトンの長さ」を決めてそこに近いのはトンということにしてみます。その常識的なトンの長さは具体的にどれぐらいどれぐらいでしょう何ミリ秒なんでしょう?うーん、正直そこに陥りたくないのですが...うーん...50ms ぐらい?
まったく自信ないが 50ms で設定してみましょう。50 ms 前後だったらトン、それより長かったらツーで一個目の信号を判断、あとは実際のタイミングを蓄積していって正確な「トン」の長さを更新してゆきます。それで判断してトンを . ツーを - で表示してみたところ、以下のようになりました。ちなみにこの辺からラズパイのじろ君でプログラミング・実行していきました。相棒のたろ君は近頃寝っぱなしです
naoki@jiro:~/workspace/morse/src $ ./read_morse ../hello_world.wav
.... . .-.. .-.. --- --..-- .-- --- .-. .-.. -..例題の符号は “HELLO, WORLD” です。どうやら合っているようです。ここまで来たらあとは先日組んだデコーダを実行して(実際には少し改造しましたが)
naoki@jiro:~/workspace/morse/src $ ./read_morse ../hello_world.wav
.... H . E .-.. L .-.. L --- O --..-- , .-- W --- O .-. R .-.. L -.. Dえーこれで完了?いやいや、そんなに簡単じゃないはず。でもまあ一通りの動く機構は用意できたわけです。大まかにこんな仕組みです

デコードはアルゴリズムの世界ですから多少の速い遅いやメモリを食う食わないがあったとしても、ここ由来の誤動作は起きにくいでしょう。問題は音信号分析とタイミング判断です。音信号分析はまだ手を付けておらず、後日しっかりと検討するとして、タイミング判断部は「常識的な長さ」が基準ではどうにもこころもとないのです。試しに、同じ例題信号を半分のスピードにしてみてそれでも正しく読めるか見てみましょう
naoki@jiro:~/workspace/morse/src $ ./read_morse ../hello_world_slow.wav
- T - T - T - T - T - T - T - T - T -- M -- M --- O ------ ? .-- W --- O --. G --.. Z -.. D
全くダメです。タイミング判断部の出だしは違う発想で作る必要があります。モールス信号は ITU から規格というか推奨が出されていて、タイミングも2章で定義されています。信号と信号の切れ目、文字と文字の間の切れ目のスペースの幅もそれぞれ 1 dot、3 dot と決まっています。最初の版では一番最初の信号の長さだけでトンかツーかを決めていましたが、そこでは判断を保留して、次のスペースが来たところで判断するのではどうでしょうか?最初のスペースがいきなり文字の切れ目というのはそうそうないでしょうから、最初のスペースは 1 dot と仮定してしまいます。この仮定は正しくない場合があるのですが、この例題のように仮定が正しい場合正常動作するか見てみることにします。スペースからわかった 1 dot の長さに対して最初の信号は同じぐらいなのか長いのかでトンツーの判断ができます。その機構を実装に組み込んでみると
naoki@jiro:~/workspace/morse/src $ ./read_morse ../hello_world_slow.wav
.... H . E .-.. L .-.. L --- O --..-- , .-- W --- O .-. R .-.. L -.. D今度はいいみたいです。今回の記事はここまで。タイミング判断はまだまだいいかげんで誤動作しまくりそうなので、次回以降そこを強化していきます。
ソースコードは github に上げました https://github.com/naokiiwakami/morse-code-reader
参考にしたサイト 大変お世話になりましたありがとうございます
https://blog.willemmelching.nl/random/2020/05/10/morse – 「例題ファイル」使わせてもらいました
https://morsecode.world/international/timing.html – モールス信号のタイミングについて
https://en.wikipedia.org/wiki/Window_function – FFT の前処理にはウィンドウをかけないと
https://www.math.wustl.edu/~victor/mfmm – FFT の実装使わせてもらいました
https://nullprogram.com/blog/2020/12/31 – モールス復号のアルゴリズム参考にしました
https://en.wikipedia.org/wiki/Morse_code – やっぱり助かる wikipedia
https://www.itu.int/dms_pubrec/itu-r/rec/m/R-REC-M.1677-1-200910-I!!PDF-E.pdf – モールス信号の規格、ソースにはあたらないとね
