
モールス信号は、「トンツー」の組み合わせでアルファベットや数字を表します。スイッチ一個で文章が伝達できるとても便利なコードで長い歴史を持っています。今でも便利に使えそうですけど、僕は昔からモールス符号、覚えられません。モールス符号は人間が理解できるように作られていますが、どうにも覚えられないし、機械に読ませられないかな?と思ってやってみることにしました。まずは一連の処理のうち一番簡単そうな「トンツー」を文字に変換する部分からやってみます。ということで、先日二つの実装を紹介したのですが、プログラムだけ見ると難解かもしれません。あれはこういう仕組みで動いてますよ、という記事です。

「トンツー」をデコードして文字に戻す手法として多分思いつきやすいのは「テーブル参照」と「二分探索」だと思います。テーブル参照は「トンツー」と文字の対応表を作って入ってきたコードに対応する方法です。プログラムはすごくわかりやすくて、例えば Python で心臓部を書くとこんな感じ
CODE_TABLE = {
".-": "A",
"-...": "B",
"-.-.": "C",
"-..": "D",
".": "E",
"..-.": "F",
"--.": "G",
"....": "H",
...でもこの方法ですと一文字分のコードが全部入力されるまでデコーダは動けず、入力が完了してからデコードが開始されるので、CPU の使用パタンが不均一になってしまい、非力なプロセッサで処理する場合問題になりそうです。非力でなくてもリアルタイム処理を行う場合不利な方式です。それに、文字の入力が完了するまで過去に入力した「トンツー」を覚えていないといけません。そのプログラミングも面倒そうですし小さいですが無駄なメモリを食ってしまうことになります。
もう一つの方法が二分探索です。モールス符号は、「トン」と「ツー」の二種類しかないので、下の図のように、二分木を作って、入ってきた「トン」と「ツー」に従って木をたどって行くと目的の文字にたどり着きます。この方法では、今木のどの場所にいるかだけ覚えておけば良く過去の「トンツー」は忘れて構わないため実装が単純になります。
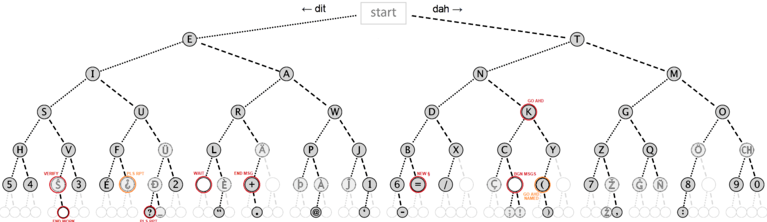
どう木を実装するかにもいろんなやり方が考えられます。自然に考えたら木の節を以下のように定義して繋がりをくみ上げてゆけば良いのですが
struct TreeNode {
char character;
struct TreeNode *dit;
struct TreeNode *dah;
};もっとメモリを使わないやり方はあるでしょうか?というのが先日紹介した実装です。
int morse_decode(int state, int c) {
static const unsigned char table[] = {
0xac, 0xca, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x80, 0x86, 0x92, 0x80, 0x94, 0x82, 0x80, 0x80,
0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x46, 0x50, 0x0e, 0x00,
0x00, 0x00, 0x26, 0x52, 0x34, 0x24, 0x00, 0x00, 0x56, 0x44,
0x0c, 0x0a, 0x48, 0x4c, 0x00, 0x04, 0x28, 0x54, 0x00, 0x00,
0x30, 0x40, 0x2a, 0x38, 0x18, 0x1a, 0x00, 0x00, 0x00, 0x00,
0x3a, 0x00, 0x32, 0x4e, 0x3e, 0x3c, 0x2e, 0x16, 0x00, 0x08,
0x42, 0x36, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00,
};
int index = (-state) & 0x7f;
switch (c) {
case 0: case ' ': return (table[index] & 0x80) == 0 ? index / 2 + '/' : 0;
case '.': return -table[index];
case '-': return -table[index + 1];
default: return 0;
}
}この一つ目の実装は、木の中で同じ文字は一回しか現れないことと、表現する文字が、数字とアルファベットと ascii コード上比較的連続した領域にあることを利用しています。探索木は table で構築していますが、このテーブルは2バイト一組で、テーブル内の位置が文字の種類を示しています。文字の並びは ascii コードの / から Z と同じです。以下のような感じ
0xac, 0xce : /
0x00, 0x00 : 0
0x00, 0x00 : 1
0x00, 0x00 : 2
...
0x46, 0x50 : A
0x0e, 0x00 : B
...2バイトのデータは、それぞれ次に 「トン (. dit)」が来た時、「ツー (- dah)」が来た時のテーブルのジャンプ先を示しています。ただ、木を構築するにあたって考慮する必要のあることがあります。それは、探索木の中には、次に進んだらエラーになる「行きどまり」と、そこで止まったらエラーになる「通過点」があるということです。行きどまりの例は、数字の0 (—–)、通過点の例はコード (—-) の割当先です。ここは 0 に至る通過点ですが、割り当てられている文字がなくここで止まったらエラーです。このテーブルでは 0 の値は行きどまりを示していて、そこから次のコードが来たらエラーです。テーブル値の 8bit データのうち、MSB 1 ビットを割いて、そこが 1 だった場合通過点であることを示します。デコーダが終了コード ('\0' または ' ') を受け取った場合、今いるテーブル値の MSB をチェックして 1 だったらエラー、0 だったら 残り 7 bit の値に ‘/’ の ascii 値を加えると符号が示している文字になります。
以上が一つ目の実装、探索木テーブルのサイズは 88 byte になりました。
同じぐらい単純な実装で、さらにテーブルのサイズを小さくしたのが二番目の実装です。
int morse_decode(int state, int c) {
static const unsigned char table[] = {
0x03, 0x5b, 0x97, 0x6b, 0x4b, 0x7f, 0x7b, 0x93, 0x9b, 0x8d,
0xa3, 0x57, 0x73, 0x63, 0x83, 0x67, 0x9e, 0x5c, 0x02, 0x74,
0x00, 0x84, 0x6e, 0x4d, 0xa4, 0x50, 0xa8, 0xad, 0x88, 0x01,
0x03, 0x18, 0x14, 0x00, 0x10, 0x00, 0x00, 0x00, 0x0c, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08, 0x1c, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x24,
0x00, 0x28, 0x04,
};
int value = table[-state];
switch (c) {
case '\0': return value >= 0x4 ? (value >> 2) + '/' : 0;
case '.': return value & 0x1 ? state * 2 - 1 : 0;
case '-': return value & 0x2 ? state * 2 - 2 : 0;
default: return 0;
}
}こちらも二分探索ですが、二分木の実装方法が違っています。一番目の実装では、テーブル内の位置は文字を示していましたが、二番目の実装では、配列を使った暗黙の木構造を使って、コンパクトに木を実装しています。テーブルの値はその経路での文字を示しています。
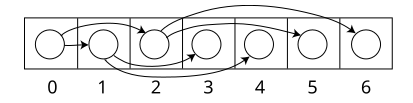
この方法でもやはり「行きどまり」と「通過点」について考慮する必要があります。行きどまりを設けるためには、各節点で「次に言って良いか」のフラグが必要になります。そのためにテーブル値の LSB 2 ビットを割いています。LSB 1 ビット目が 1 なら「トン」について進んでよく、LSB 2 ビット目が 1 なら「ツー」について進んで大丈夫です。0 ならばエラーです。そしてテーブル値 8 ビットのうち残り 6 ビットが「文字」に割り当てられています。ここで、文字の値が 0 だった場合は「通過点」を示していてそこで止まったらエラーです。それ以外だと出力文字コードなわけですが、一番大きい Z のascii コードは 90 で、6 ビットで表現できる 63 を超えているため (値0 は予約されているので 64 – 1) そのまま格納はできません。でも、一番小さい 0 の ascii コードは 48 で、コードの範囲は実は 90 – 48 = 42 しかありません。これならなんとかなりそうです。 そこで、実際の ascii コードから 47 を引いた値をテーブルに入れれば、1 が ascii 48 で 0、43 が ascii 90 で Z、しっかり 6 ビットの範囲に収まります。これが二番目の実装です。テーブルは 63 バイトにまで減らせました。
コードは短いのですが中でやっていることを説明したら長くなってしまいました。野暮です
でもこのような、コードは短くても中身は結構複雑、というアルゴリズムに出会うことは珍しいので楽しんでもらえたらうれしいです。
